Vsuvka autora mimo téma (ale koneckonců je to blog:) )
Po delším výpadku v psaní blogu jsem zpátky a budu opět pravidelně přispívat. I s psaním blogu je to podobné,
jako se vším ostatním. Na „chvíli“ vypadnete a pak se těžko naskakuje. Psaní článků pravidelně je poměrně
časově náročné a když to člověk přičte k práci, rodině a tréninku triatlonu (letošním cílem je Moraviaman na
tratích železného muže v Otrokovicích a to si žádá přípravu). Něco musí jít trochu do pozadí. A trošku jsem se
méně věnoval komunitě. Ubylo článků na blogu a také přednášek bylo o něco méně, než 2016. Promítla se i
lehká motivační krize když několik měsíců čekáte na update, který nepřichází. Novoroční předsevzetí (ano
opravdu v únoru), je opět zamakat na doručování informací ze světa Business Inteligence. Většina článků bude
věnována Power BI. Nechci moc tříštit úsilí. Při rozhvoru na jedné komunitní akci mě inspirovala kamarádka
(tímto Magdu zdravím:) ) Jestli nechci zkusit dát na blog i číslo účtu, že jí v minulosti blog pomohl při hledání
informací. Že kdybych ho tam měl, možná by mi tam i něco poslala. Dlouho jsem o tom přemýšlel a říkám si
nakonec, proč ne. Pokud byste cítili silnou potřebu podpořit mé snahy o doručování novinek a praktických
zkušeností z BI světa. Zde je: 670100-2201291528/6210
Také ho přidám do kontaktní sekce. Nic to ale nemění na tom, že tento blog je nekomereční záležitost. Píši jej
dobrovolně ve volném čase bez nároku na odměnu, jako podporu české a slovenské BI komunity.
Dost bylo vsuvek, pojďme na samotný obsah článku.
Článek
O analýze nákupního košíku jsem měl přednášku na třech konferencích. SQL Saturday v Praze, G2B Teched v
Brně a Show IT v Bratislavě. Stejné téma, možná lehce jiné pojetí a různá publika. Třikrát a dost. V Praze
vzniknul tento záznam https://www.youtube.com/watch?v=QkMJCW7cjEs takže, pokud Vám to uteklo, můžete
se podívat. Tento článek přináší doprovodné materiály a zdrojové kódy. Co bylo obsahem přednášky pro Ty z
Vás, co jste ji neviděli.
Proč vlastně tohle téme
Pracuji v Dixons Carphone, což je společnost zabývající se retailem. Analýza toho, co se kupuje pohromadě je
tedy v rámci firmy celkem zajímavé téma. Když se mluví o analýze nákupního košíku běžně, většinou se člověku
vybaví technologie jako Machine Learning, Data mining. Což jsou skvělé přístupy a s tím spojené technologie,
ale ne každá společnost v týmu má lidi, kteří tyto metody a principy ovládají. Hlavní důvod přednášky byl, když
to řešíme my, možná i někdo jiný. Tak proč se nepodělit o svůj přístup a řešení.
Pár bodů k zamyšlení
Můžu a chci sledovat chování zákazníků (myšleno jako konkrétní člověk se jménem, příjmením adresou atd).
První věcí k zamyšlení je o jaké formě prodeje se vlastně bavíme. Online vs. obchod. U online nákupu jsme
schopni jednotlivé zákazníky rozlišit, protože nám tak nějak o sobě musí něco sdělit. Alespoň pokud si chce
zboží vyzvednout :). U nákupu v kamenném obchodě je to složitější. Tam pokud si člověk nevyřídí kartičku na
sbírání bodů zákazníka bez kamerového systému nerozlišíme.
Další faktor je četnost nákupů zákazníka. Asi bude rozdíl, jestli prodáváte potraviny. Nebo třeba elektroniku. U
online obchodů ze dvou nákupů velkých spotřebičů za rok asi hůř budete dělat závěry, než když u jednoho
zákazníka, který pravidelně kupuje deset rohlíků a dva lahváče.
Technologická perspektiva je o tom, jaké technologie máte k dispozici a jaké technologie ovládají vaši
kolegové/zaměstnanci. Neméně důležité je: kdo a jakou formou má získávat ze systému informace. Jestli se
bude jednat o stroj (našeptávač v eshopu), nebo člověk odpovědný za nacenění produktů/marketingové akce
atd.
Chci vůbec ukládat informace o zákazníkovi jako individualitě v BI systému? V e-shopu se tomu nevyhnu, ale v
datovém skladu by mi možná stačily informace o transakci. Jaké položky byly pořízeny na jedné transakci můžu
sledovat jak pro eshop, tak kamenný obchod. A je mi „jedno“ jestli se zákazník jmenuje Pepa, nebo Karel, nebo
třeba Unknown (v případě kamenného obchodu). To že v BI citlivé informace nechceme, na to může mít i vliv
nařízení GDPR.
Jaké byly požadavky
Výsledek řešení prezentovaný v tomto blogu je výstupem na základě požadavků byznysu. Ty byly následujcí
interaktivní report přístupný uživatelům pro interaktivní analýzu
sledování základních KPI pro primární produkt a produktů co se prodali s produktem primárním
- (attached). Metriky například Částka s daní, Částka bez daně, Marže, Počet kusů a další
security model, omezení produktové hierarchie na úrovni primárního produktu (o row level security v
- Power BI jsem psal zde http://www.neoral.cz/2016/04/power-bi-role-zabezpeceni.html)
možnost měnit vstupní parametry v průběhu analýzy (časové období, kanál prodeje, parametry
- produktové hierarchie a další)
čím dříve to bude, tím lépe
Jaké jsem zvolil technologie a proč
SQL Server jako vrstva která drží surová data, struktury bylo potřeba jen trochu uzpůsobit potřebám
analytického modelu.
Power BI moje volba číslo jedna, když je požadavek na interaktivní report
SSAS (SQL Server Analysis Services) díky svým analytickým možnostem a obavám z výkonnosti řešení a objemu
dat. Dalo by se použít jen Power BI, ale mohli bychom narazit na 1GB limit. SSAS umožňují také možnost dle
potřeby postavit SSRS report, nebo ad hoc připojení přes Excel.
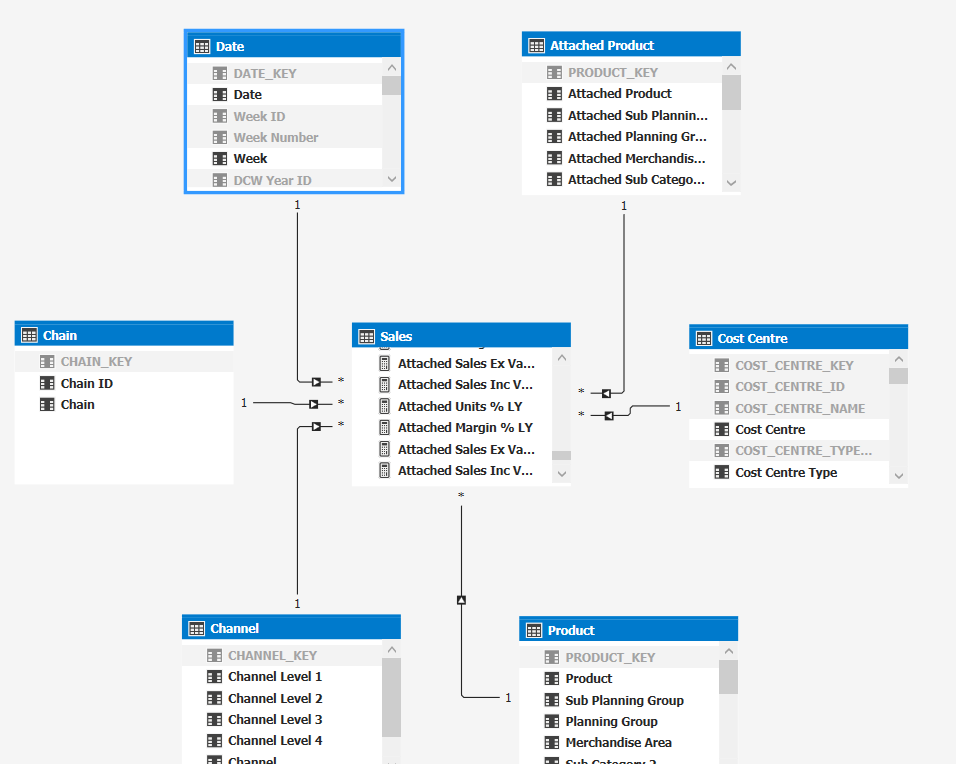
Logický datový model
Schéma hvězda, kde se vše točí kolem prodejů. Možnost analyzovat přes Datum, primární produkt (Product),
související produkt (attached product) a další dimenze.
Dotaz pro získání informací o prodejích
Dochází zde k namnožení záznamů aby na transakci ke každému primary produktu byla vygenerována ještě
Attached část. Ale tak, aby nedošlo k ovlivnění celkového výsledku. (Total sales musí sedět na to co se skutečně
prodalo).
;WITH DATA_CTE AS
(
SELECT
f.CHAIN_KEY
,f.CHANNEL_KEY
,f.TRANSACTION_DATE_KEY
,f.COST_CENTRE_KEY
, f.PRODUCT_KEY
,f.TRANSACTION_KEY
,SUM(f.SALES_INC_VAT) as SALES_INC_VAT
,SUM(f.SALES_EX_VAT) as SALES_EX_VAT
,SUM(f.TAB_MARGIN) as TAB_MARGIN
,SUM(f.UNITS) as UNITS
FROM dbo.UVW_FACT_SALES f
GROUP BY
f.PRODUCT_KEY
,f.TRANSACTION_KEY
, f.CHAIN_KEY
,f.CHANNEL_KEY
,f.TRANSACTION_DATE_KEY
,f.COST_CENTRE_KEY
)
SELECT
/*header*/
p.CHAIN_KEY
,p.CHANNEL_KEY
,p.TRANSACTION_DATE_KEY
,p.COST_CENTRE_KEY
/*primary*/
,p.PRODUCT_KEY
,p.TRANSACTION_KEY
,CASE WHEN p.PRODUCT_KEY = a.PRODUCT_KEY THEN p.SALES_INC_VAT ELSE NULL END as SALES_INC_VAT
,CASE WHEN p.PRODUCT_KEY = a.PRODUCT_KEY THEN p.SALES_EX_VAT ELSE NULL END as SALES_EX_VAT
,CASE WHEN p.PRODUCT_KEY = a.PRODUCT_KEY THEN p.TAB_MARGIN ELSE NULL END as TAB_MARGIN
,CASE WHEN p.PRODUCT_KEY = a.PRODUCT_KEY THEN p.UNITS ELSE NULL END as UNITS
/*attached*/
,a.PRODUCT_KEY AS ATTACHED_PRODUCT_KEY
,CASE WHEN p.PRODUCT_KEY <> a.PRODUCT_KEY THEN a.SALES_INC_VAT ELSE NULL END as ATTACHED_SALES_INC_VAT
,CASE WHEN p.PRODUCT_KEY <> a.PRODUCT_KEY THEN a.SALES_EX_VAT ELSE NULL END as ATTACHED_SALES_EX_VAT
,CASE WHEN p.PRODUCT_KEY <> a.PRODUCT_KEY THEN a.TAB_MARGIN ELSE NULL END as ATTACHED_TAB_MARGIN
,CASE WHEN p.PRODUCT_KEY <> a.PRODUCT_KEY THEN a.UNITS ELSE NULL END as ATTACHED_UNITS
FROM DATA_CTE AS p /*primary*/
LEFT JOIN DATA_CTE AS a /*attached*/
ON p.TRANSACTION_KEY = a.TRANSACTION_KEY
Trocha DAX výrazů v datovém modelu
Se měla právě postarat, aby byla zachována správnost výsledků. Dva příklady
Primary Sales Ex Vat:= CALCULATE(SUM(‘Sales’[SALES_EX_VAT]);all('Attached Product’))
Daný vzorec říká, že metrika má ignorovat dimenzi Attached Product.
Attached Sales Ex Vat:= CALCULATE(SUM(‘Sales’[ATTACHED_SALES_EX_VAT]);ALLSELECTED('Product');EXCEPT('Attached Product';'Product'))
Attached metriky mají ve výpočtu ignorovat dimenzi primární produkt. Attached je to, co vznikne po množinové
operaci Except mezi Attached Produkty a produkty primárními v daném kontextu.
Ukázky z hotového reportu uvidíte nejlépe na videu. Stejně jako popis případných nejasností. Těžko vložit
veškeré myšlenkové pochody a několik týdnů vývoje a ladění do pár řádků v blogu. Navíc tenhle je už dlouhý.
Materiály
Contoso prodává elektroniku stejně jako Dixons, takže nejvhodnější kandidát. Poté jsem musel vytvořit pohledy,
které názvy sloupců a struktury učesaly do stejné podoby, jako byly nad daty produkčními.
Závěr
Ústřední myšlenkou je, že výběr technologie je dán požadavky na řešení. Analýza nákupního košíku se dá
provádět i s pro širokou SQL komunitu s dostupnými nástroji, jako je SQL Server a Power BI.