Dnešní článek bude trochu z jiného soudku. Už od SQL Server 2008 R2 Microsoft nabízí svoji appliance pro masivní paralelní zpracování dat (MPP Masive Parallel Processing). Řešení pro ty největší datové sklady se jmenuje Parallel Data Warehouse (PDW). Pár let zpátky začal Microsoft říkat řešení Analalytics Platform System, protože k PDW přidal i možnost dotazovat se na nestrukturovaná data z Hadoop regionu díky Polybase... Pokud jsem Vás nezabil tímto úvdoníkem, tak už nevím čím. PDW není dvakrát cenově dostupná hračka. V České republice vím o jediné společnosti, která PDW má k dispozici (a to hned dvakrát). Touto společností je můj zaměstnavatel Dixons Carphone plc. (v Česku zastoupena Dixons Retails SSC s.r.o.). PDW se budu věnovat v samostatném článku někdy v budoucnu. Jako lektor jsem se bavil se spoustou firem a poslouchal, jak řeší jestli koupit BI edici, nebo spíš skončí na Standardu protože se licencuje na jádra. Enterprise edice by byla krásná, ale že je moc drahá a budou muset vystačit se Standardem i když funkce budou chybět.
No a teď si představte rack (nebo třeba 6ti rack), do kterého narvete několik Enterprise SQL Serverů s redundancí, control nodem a že to spolu všechno mluví a parallelně zpracovává dotazy. Megaželezo + Megalicence = Megapálka :) 1,340 milionu dolarů za full rack jednorázová pořizovací cena. A kdo z Vás tohle má... :) V porovnání s konkurencí ale stále vychází PDW od Microsoftu levně viz tabulka na straně 4 (bez Hadoop regionu) http://www.valueprism.com/resources/whitepaper/APS%20TCO%20Whitepaper%20-%20FINAL.pdf
A pak zjednodušeně řečeno inženýři z Microsoftu PDW zvirtualizovali a vznikl Azure SQL Data Warehouse. Tímto se dostupnost MPP platformy výrazně posouvá blíž běžným firmám. Nastalo mi ideální období 2 dny do expirace kreditu z MSDN předplatného, tak se jde testovat.
Tvorba DW
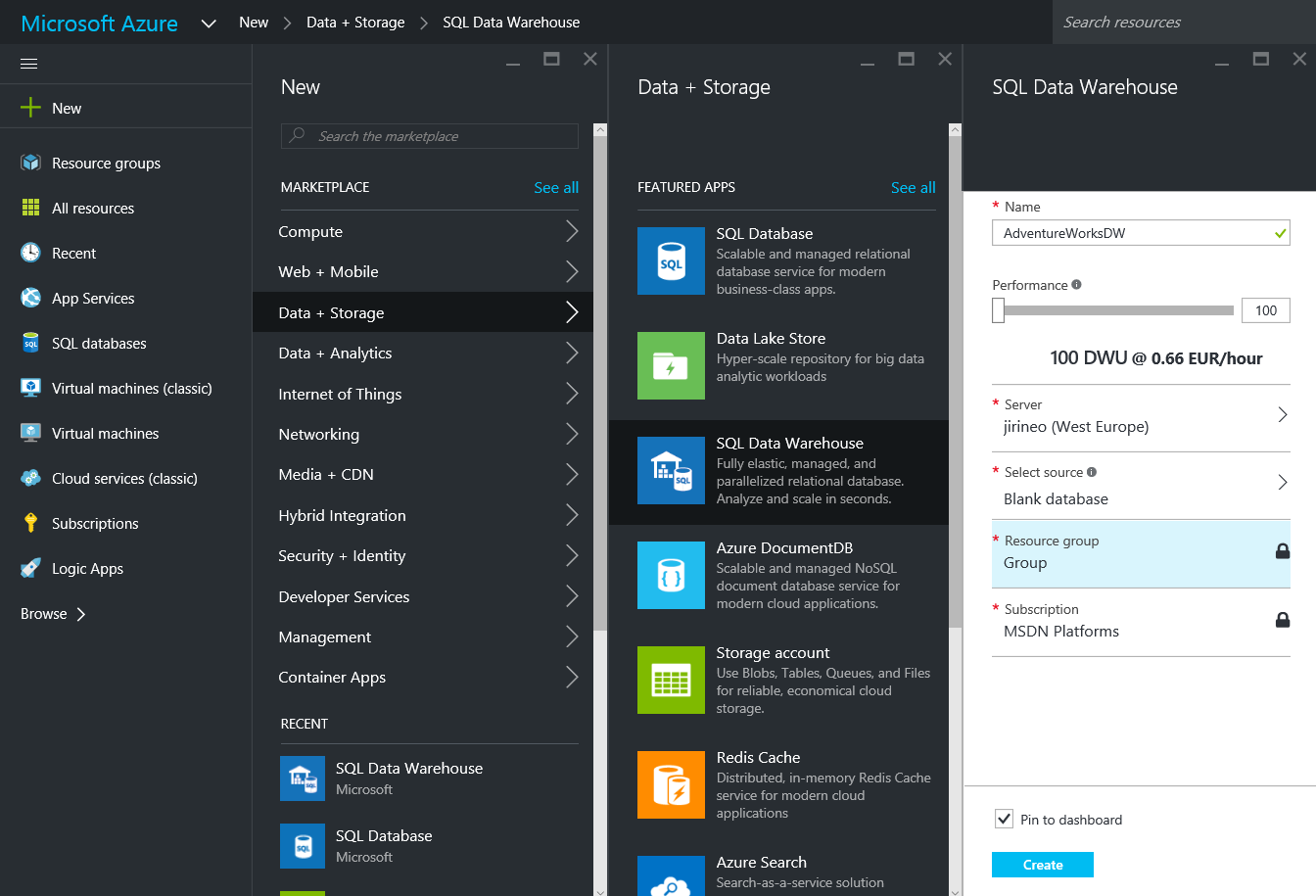
V novém Azure Portálu – New – Data + Storage – SQL Data Warehouse
Povinné údaje
Název databáze. Posuvník týkající se výkonnosti podobný toho co je dostupný u Azure SQL Database. Výběr serveru, pokud zatím žádný vytvořený nemáte, vytvoří se nový. Resource group a subscription, ze kterého budete platit. Mezi databázemi je možno vybrat ukázkovou a koho to tu máme? Ejhle Adventure Works. To už jsem někde viděl. Jen doufám, že největší faktová tabulka bude mít víc jak 60 000 řádků. Tvorba databáze trvá několik málo minut.
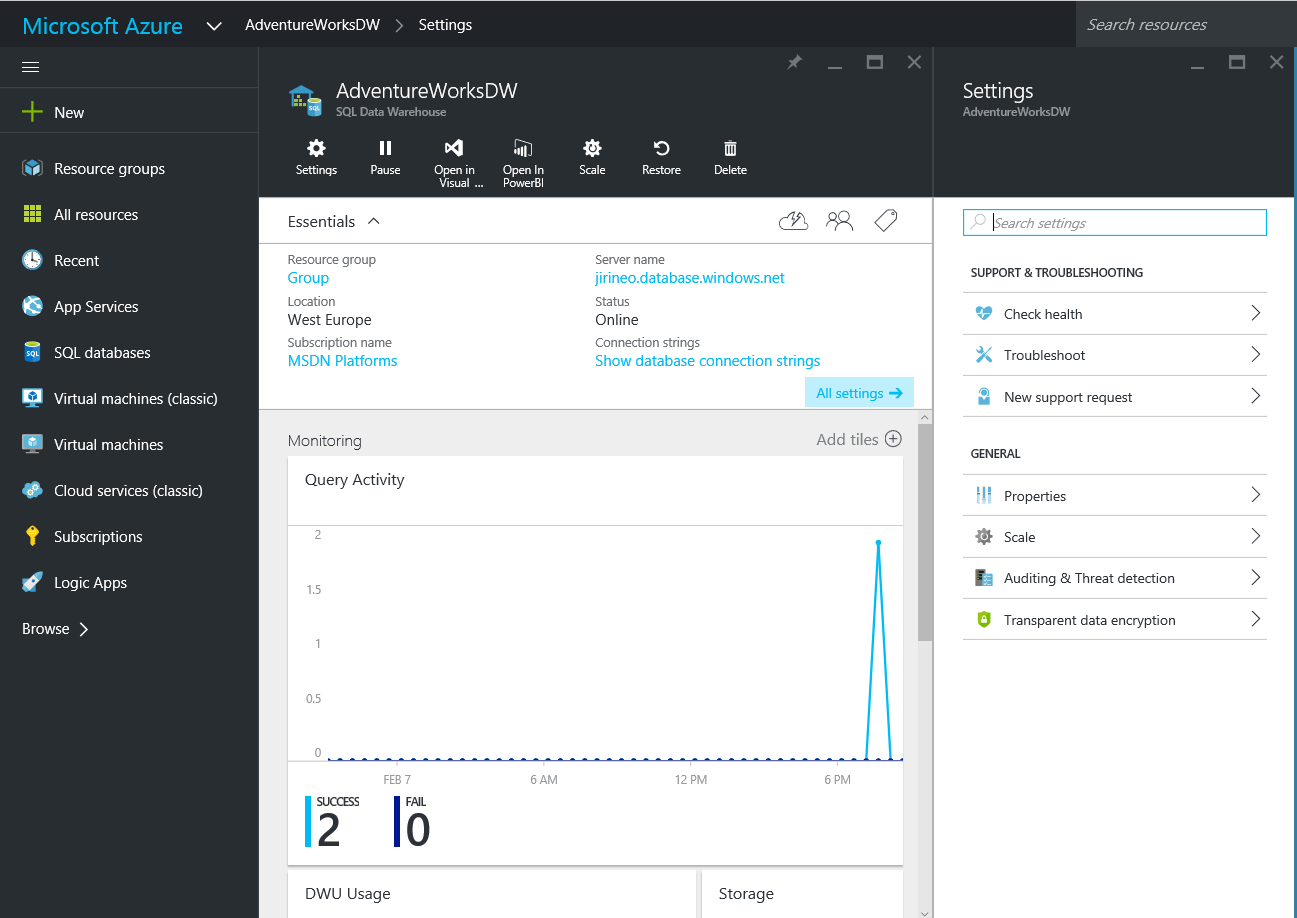
Po tvorbě databáze se zobrazí následující obrazovka.
Monitor aktivity co se děje uprostřed. Důležitá nastavení včetně connection stringu. Nahoře ovládací lišta a po pravici podpora. Chcete-li se připojit z klientských nástrojů, můžete použít buď Visual Studio, nebo PowerBI. Management studio se připojí, ale neumí číst správně metadata.
Připojuji se přes visual Studio a koukám na velikost faktové tabulky FactResellerSales. Nezklamala a má svých klasických 60855 záznamů. Tady výkon neotestuji, takže si data trochu namnožím. Faktová tabulka obsahuje data po dnech, tak si je rozpočítám na minuty. Nechce se mi s tím moc trápit, tak to čísla rozpočítám na minuty rovnoměrně.
Pokud chci psát dotaz proti Azure SQL Data Warehouse musím zvolit správnou šablonu a sice .dsql stejně jako v případě PDW. Jedná se o zkratku Distributed SQL. V Azure SQL Data Warehouse máme 2 typy tabulek, replikované a distribuované. Replikované tabulky obsahují stejná data na každém uzlu. Hodí se například pro dimenze. Distribuované tabulky jsou naopak rozbity na několik serverů podle hashovacího klíče. Hodí se pro velké faktové tabulky. Na rozdíl od klasického partitioningu se hodí distribuovat tabulku podle klíče, který umožní rozprostření na výpočetní nody rovnoměrně. Nejde nám o to, abychom eliminovaly nehodící se partitions při čtení, ale naopak chceme rovnoměrně číst na několika uzlech zaráz.
Z výkonového pohledu je výhodnější než vytvořit tabulku a do ní provést insert udělat to příkazem v principu podobným SELECT * INTO tabulka FROM DATA až na to, že SELECT INTO zde nefunguje. Používá se zde syntaxe tzv. CTAS (CREATE TABLE AS SELECT). Dokonce je v mnoha případech rychlejší tabulku dropnout a znovu vytvořit příkazem CTAS, než do ní dělat insert/update.
Nová faktová tabulka z původní Fact Reseller Sales by se dala vytvořit příkazem
create table fact_reseller_sales
with (Distribution = hash(productKey))
as
with dim_hour as (
select top 24 hour_key = row_number() over(order by name)-1 from sys.columns
),
dim_minute as (
select top 60 minute_key = row_number() over(order by name)-1 from sys.columns
)
SELECT
f.*
,time = cast(cast(h.hour_key as varchar(2)) + ':' + cast(m.minute_key as varchar(2)) as time)
,Sales = salesamount /24
FROM factresellersales f
CROSS JOIN dim_hour h
CROSS JOIN dim_minute m
Dalo by se to napsat i krásněji? Možná ano, ale je půl desáté večer a já jsem si řekl, že prostě ne :)
Všimněte si několika specifik. Zaprvé Create Table As Select.
Zadruhé distribution = hash(Hashovací klíč). Pro replikovanou tabulku byste použili
create table fact_reseller_sales
with (Distribution = round_robin )
as
Za třetí na klasickém SQL Serveru bych použil nejspíš rekurzivní CTE (Common Table Expression), zde nemohu, protože mi to král bramborových lidí nedovolí (DSQL).
Protože jsem škrt a šetřil jsem na posuvníku (článek dopisuji po zahájení nového účtovacího měsíce) s výkonem (SCALE 100 DWU), tvorba tabulky trvala 7:21 a obsahuje 87 631 200 řádků. To bude na pokusy s výkonem trochu lepší.
To byl zápis, co čtení? První co zkusím je počet řádků a celková suma.
SELECT
Rows_count = count(*)
,Sales = sum(f.sales)
FROM Fact_reseller_sales f
Výstup získávám za 16 vteřin. Zkouším dotaz, kde využiji hashovací klíč.
SELECT
c.englishproductcategoryname
,s.englishproductsubcategoryname
,p.modelname
,p.englishproductname
,Rows_count = count(*)
,Sales = sum(f.sales)
FROM Fact_reseller_sales f
JOIN dimproduct p
ON p.productkey = f.productkey
JOIN dimproductsubcategory s
ON p.productsubcategorykey = s.productsubcategorykey
JOIN dimproductcategory c
ON c.productcategorykey = s.productcategorykey
group by
c.englishproductcategoryname
,s.englishproductsubcategoryname
,p.modelname
,p.englishproductname
Dotaz pouštím opakovaně a měním DTU, abych porovnal cenu a výkon :) DTU je zkratka Database Transaction Unit, která nám vypovídá o poměru, kolik transakcí za vteřinu by měl server zvládnout. Přesná definice DTU v angličtině https://azure.microsoft.com/en-gb/documentation/articles/sql-database-service-tiers/#understanding-dtus Škálování trvá v řádu jednotek minut. Výkonové srovnání můžete shlédnout v přehledné tabulce. Zkušenost je taková, že po změně škálování, případně stopu/startu databáze je Azure SQL Data Warehouse nějaký líný. Když běží nějakou dobu, je to diametrálně lepší. Proto dva časy v tabulce
DWU
|
Eur/h
|
Čas 1.
|
Čas 2.
|
100
|
0.66
|
|
1:15
|
200
|
1.32
|
4:28
|
0:28
|
500
|
3.31
|
5:15
|
0:02
|
1000
|
6.61
|
2:40
|
0:02
|
Závěr:
Azure SQL Data Warehouse přináší možnosti MPP masám díky Azure. Za zásadní výhodu považuji možnost Warehouse pausnout a tím pádem neplatit za výkon. Posuvník se škálováním je také super, potřebujete masivní výkon pro zpracování dat ve špičce? Ohulíte DTU posuvník, až systém není využíván, stáhnete na DTU 100 nebo úplně zastavíte. Tohle s normálním SQL Serverem a koneckonců ani PDW dost dobře nejde. Tam většinou musíte škálovat hardware podle špičkového výkonu, kterého chcete dosáhnout.