Úvod
Power BI uživatelé, vydržte, článek bude relevantní i pro Vás :) Možná :)
Poměrně častou otázkou, kterou dostávám na konferencích a školení týkající se analytických služeb je: Kdy použít Multidimensional, kdy použít Tabular (Power BI běží na Tabularu).
Rychlá odpověď úplně neexistuje (a možná si to zaslouží samostatný blog post). Jedním z faktorů vstupujících do rozhodování je architektura úložiště.
Multidimensional drží data na disku, Tabular v paměti. Sami si odpovězte na otázku, čeho mají vaše servery více :)
Je ale opravdu třeba se obávat nedostatku paměti? Tabular a Power BI do paměti data komprimuje.
O tom, jak komprese ve Vertipaq úložišti funguje jsem mimo jiné povídal na WUG Days a záznam můžete shlédnout zde
Konkrétně popis enginu na přednášce vychází z knihy od Alberta Ferrari a Marca Russa:
Deffinitive Guide To DAX
Bude vycházet druhá edice, chcete-li komplet přehled, počkejte si.
Priority vývojového týmu Analytických služeb jsou zřejmé. V Tabularu je budoucnost, Multidimensional se více nerozvíjí
(průlomových novinek v Multidimenzionalu jsme se nedočkali od verze 2008) a podpora ze strany klientských aplikací, zejména Power BI, pokulhává.
A to je to, co mě v poslední době vadí nejvíce a přehodnocuji, zda držet se multidimenzionalu je dobrý nápad (a to jsem velký fanda).
Multidimenzional byl pro stávající řešení ve firmě vybrán hlavně s ohledem na funkci. Tabular nesplňoval všechny funkční požadavky, po pár letech je ale situace již trochu jiná.
Na co však v Multidimenzionalu marně čekám a začíná se z toho stávat skutečná bolest jsou session level výpočty na úrovni reportu při živém připojení. Bolestí je víc.
Udělám z toho samostatný blog post v angličtině, protože jeden moudrý člověk mi řekl ohledně mých MVP aktivit. “Chceš-li něco změnit, musí se to dostat k produktovému týmu”.
Takže přemýšlím i nad tím, jestli budu psát česky, střídat jazyky, nebo přejít komplet do angličtiny (abych lépe ovlivnil vývoj produktu). To je ale jiný příběh.
Suma sumárům, začínám ve firmě silně uvažovat nad předělání stávajícího multidimenzionálního řešení na Tabular
(pokud nebudou mé prosby vyslyšeny, nic jiného mi asi nezbyde).
Předělat něco, co vznikalo cca 4 roky nebude ale na den. Takže se můžete těšit i na návazné blog posty.
Hlavní část
Mám multidimenzionální kostku cca 11 measure groups, 27 dimenzí. Na disku v MOLAP storage zabírá 86 GB.
První základní otázka zní
Pokud bych stávající řešení chtěl předělat do Tabularu, kolik paměti si vezme model, ve kterém budu mít dostupná stejná data?
Vytvořil jsem model obsahující všechny Measure Groups. A většinu dimenzí.
Některé malé jsem vynechal, protože by cvičení trvalo zbytečně mnoho času a vliv na velikost by byl beztak minimální.
Nástroj je ke stažení zde včetně tutorialu. V podstatě se jedná o Power Pivot model postavený nad metadaty SSAS. Dá se použít jak pro analýzu Tabularu, tak Power BI.
Stačí změnit connection string na vaše SSAS a aktualizovat data.
Výsledky měření bez jakékoliv optimalizace
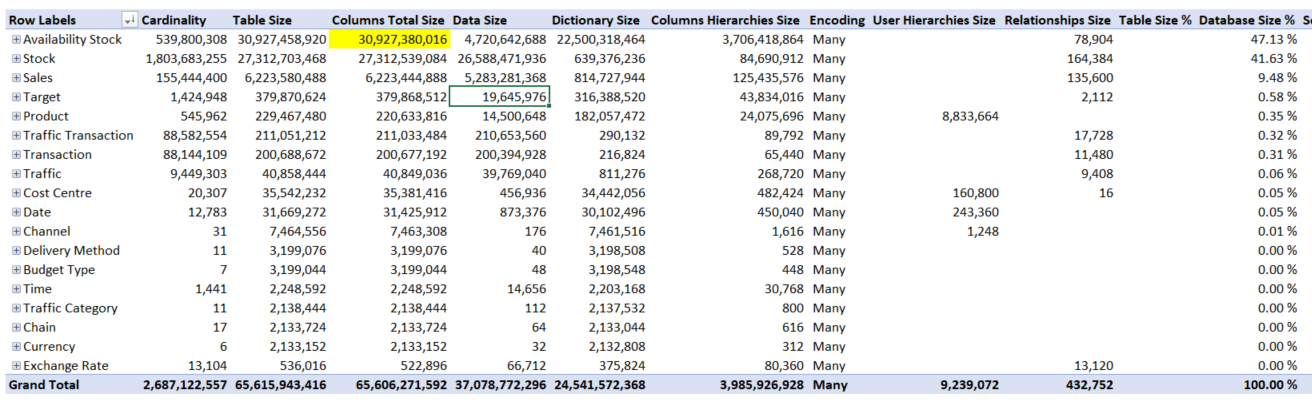
Celková velikost databáze 65,6GB bez jakékoliv optimalizace. Nejvíce místa si vzaly 2 největší faktové tabulky.
31 GB availability stock (539 milionu záznamů velká tabulka týkající se dostupnosti zboží) a 27,3 GB stock
(1,8 miliardy záznamů velká snapshotová tabulka týkající se skladových zásob).
Fakta jsou za poslední 3 fiskální roky, u nás tedy nyní cca 2,5 roku dat. Delší historii držíme v datovém skladu. Tyhle dvě faktové tabulky si vzaly 88,76% celkové velikosti.
Význam vybraných sloupců ze screenshotu:
Cardinality - u tabulky počet řádků, u sloupce počet unikátních hodnot
Table size - celková velikost tabulky (Columns size+User Hierarchies Size+Relationship Size)
Columns total size - velikost dat ve sloupcích (Data size, Dictionary size, Columns Hierarchies Size)
Data size - velikost detailních dat
Dictionary size - velikost slovníku souvisí s kompresí detaily o kompresi můžete dozvědět v článku od Alberta a Marca zde
Z předchozího screenshotu je tedy zřejmé, že Availability stock zabírá skoro 31GB a z toho 22,5 GB tvoří slovník.
Tabulka je menší do počtu řádků, ale větší do konzumované velikosti v paměti.
Jak jsou na tom asi jednotlivé sloupce?
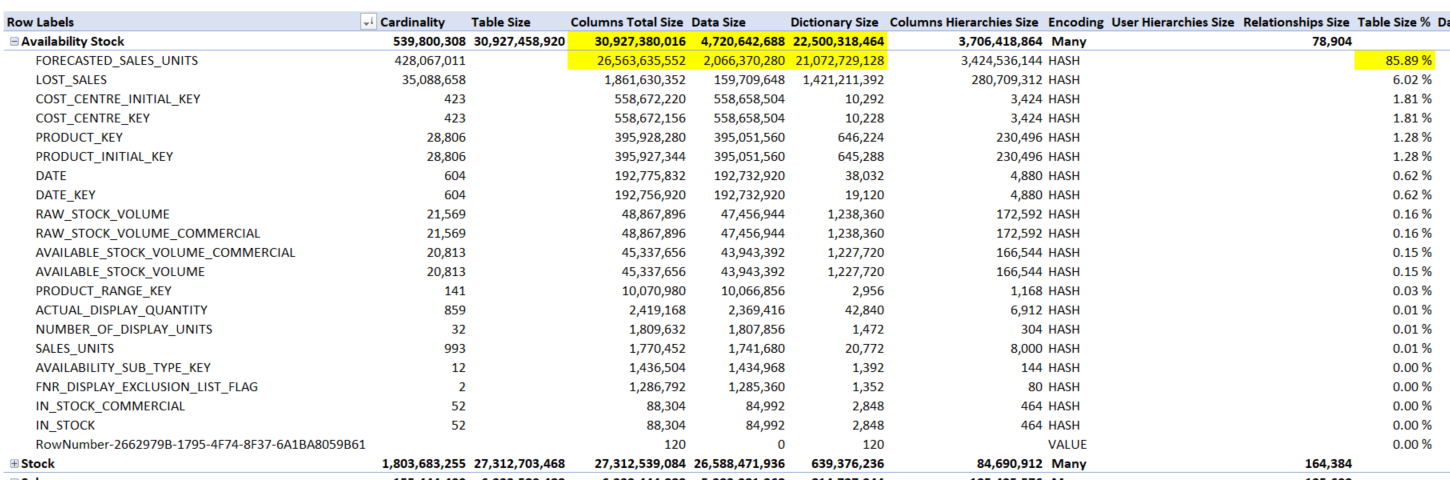
Všimněte si žlutých buněk. Tabulka 30,9 GB. Sloupec forecasted_sales_units 26,5 GB. Tedy 85,89%. Data ve sloupci 2GB, slovník pro kompresi k datům 21 GB.
To je trochu nepoměr a prostor pro optimalizaci.
Pokud vím, jak v tabularu funguje komprese, vím že velikost slovníku je dána ovlivněna datovým typem. Datový typ totiž ovlivňuje kardinalitu.
Zkontroluji datový typ u sloupce a vidím float. Můžu zachovat funkčnost modelu a při citlivé změně datového typu nepřijít příliš o přesnost?
Decimal (19,4) by mohl stačit. Provedu reload a podívejte na číla.

Změna datového typu srazila velikost tabulky z 30,9 GB na 5,8 GB. Databázi to dostalo z 65,6 GB na 40,5 GB.
Konkrétní sloupec forecasted sales units jsem dostal z 26,5 GB na 1,3 GB. To je slušné změnou datového typu u jednoho sloupce :)

Závěr
Jak bude velký model v Power BI, nebo Tabularu se nedá dopředu odhadnout jen na základě velikosti vstupních dat.
Bude záležet na množství faktorů, zejména schopnosti vertipaq engine data komprimovat. Tento článek by vám měl dát drobný návod jak na analýzu využitého místa.
Co se týká potenciální konverze stávajícího multidimenzionálního řešení do Tabularu.
Odpověď na první otázku, bude místo problém zní. Místo problém nebude. I rychlost výpočtů pro základní metriky nad tabulkou s 1,8 miliardou záznamů byla velmi slušná.
Je to ale běh na dlouhou trať a je třeba zodpovědět další dotazy. Jako například:
Půjde pokrýt celá funkčnost? Nepůjde rychlost do kytek, jak se začnou věci komplikovat složitostí byznys logiky? O tom někdy potom :)
Pěkná ukázka na float.
OdpovědětVymazatMám ale problém s velikostí typu string.
Většina sloupců má Cardinality do 100, Data Size - do 5000, ale Dictionary Size - cca 1 066 000.
Dictionary Size se zmenší pokud na sloupci nastavím Sort by …
Existuje ještě jiný způsob jak donutit VertiPaq ke kompresi slopce typu String?
Jeden sloupec má kardinalitu pod 100 a i tak takhle velký slovník? Co to je za zdrojový datový typ? U textů Vertipaq aplikuje akorát dictionary encoding a potenciálně RLE (tam pomůže řazení). https://www.microsoftpressstore.com/articles/article.aspx?p=2449192&seqNum=3
OdpovědětVymazatAle kromě snížení kardinality rozdělením do více sloupců/zkrácení textu (pokud připadá v tomhle případě v úvahu) a řazení mě nic nenapadá
Je to standardní pohled do databáze a varchar hodnoty. Dnes jsem si ověřil, že i kardinalita 1 a string o jediném znaku má tak velký slovník, dokud na něm nenastavím řazení. Takže veškeré string v první fázi velké a na všech je nutné aplikovat sort by..
OdpovědětVymazatBohužel ne vždy je nějaké řazení možné najít, protože není možné vytvořit jednoznačný klíč.
Např.: název smlouvy - 2 000 000 smluv, ale název smlouvy kardinalita 600 000. Znamenalo by to, někde bokem udělat distinct a dodat indexový sloupec a ten následně protáhnout do tabulky. Pak by sort šel.
Tak jsem konečně našel vysvětlení k těm velikostem https://www.sqlbi.com/articles/measuring-the-dictionary-size-of-a-column-correctly/
Vymazat